■ 강화학습의 기본 개념(프레임워크) 강화학습(Reinforcement Learning, RL)은 기계학습의 한 분야에서 에이전트가 주어진 환경에서 최적의 행동을 학습하도록 하는 방법입니다. ■ 강화학습의 기본 개념(프레임워크) 강화학습(Reinforcement Learning, RL)은 기계학습의 한 분야에서 에이전트가 주어진 환경에서 최적의 행동을 학습하도록 하는 방법입니다.
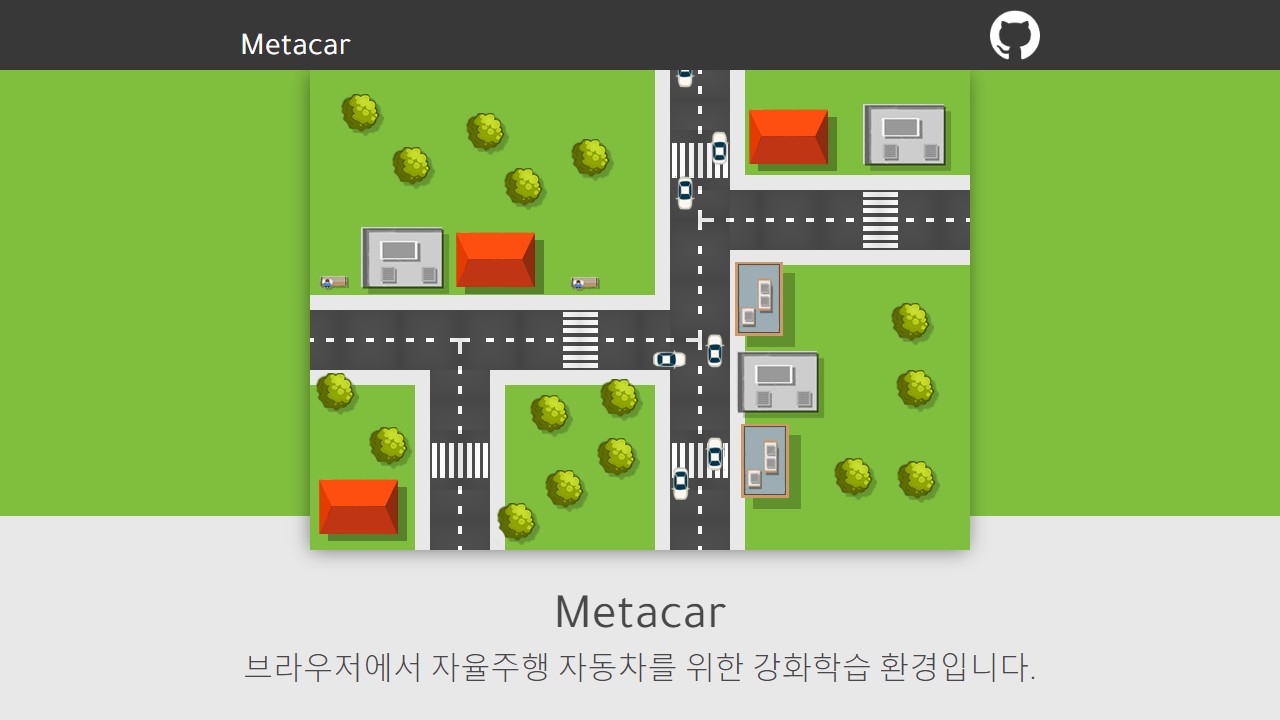
출처 : Scribbr 출처 : Scribbr
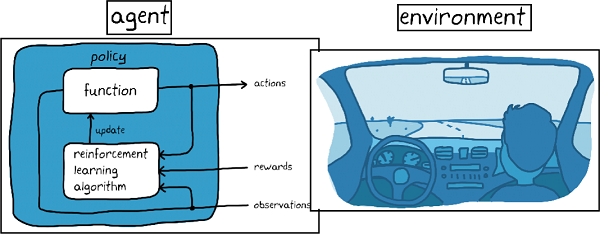
1. 에이전트: 환경에서 행동을 하는 주체입니다. 2. 환경(Environment): 에이전트가 상호작용하는 세계입니다. 3. 상태(State) : 환경의 현재 상태를 보여줍니다. 4. 행동(Action): 에이전트가 취할 수 있는 선택사항입니다. 5. 보상(Reward) : 에이전트가 특정 행동을 취한 후 환경에서 받는 피드백입니다. 보수는 숫자로 표현되며 긍정적이기도 하고 부정적이기도 합니다. 6. 정책: 에이전트가 주어진 상태에서 어떤 행동을 할지 결정하는 전략입니다. 1. 에이전트: 환경에서 행동을 하는 주체입니다. 2. 환경(Environment): 에이전트가 상호작용하는 세계입니다. 3. 상태(State) : 환경의 현재 상태를 보여줍니다. 4. 행동(Action): 에이전트가 취할 수 있는 선택사항입니다. 5. 보상(Reward) : 에이전트가 특정 행동을 취한 후 환경에서 받는 피드백입니다. 보수는 숫자로 표현되며 긍정적이기도 하고 부정적이기도 합니다. 6. 정책: 에이전트가 주어진 상태에서 어떤 행동을 할지 결정하는 전략입니다.
인기글




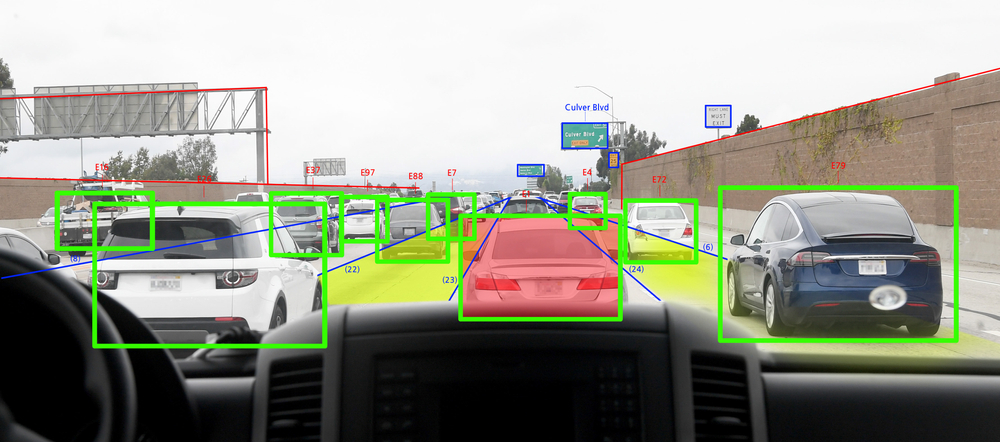
출처 : Scribbr 출처 : Scribbr
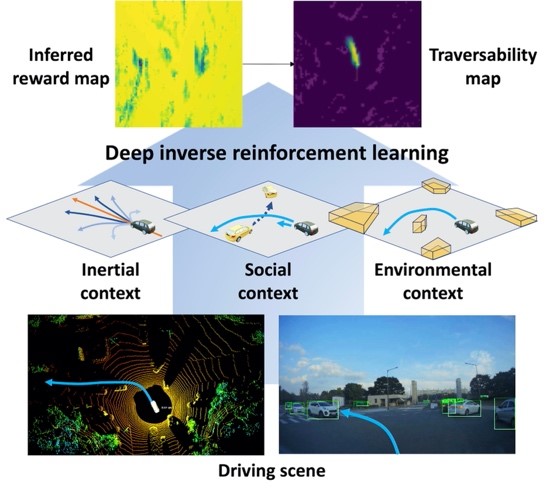
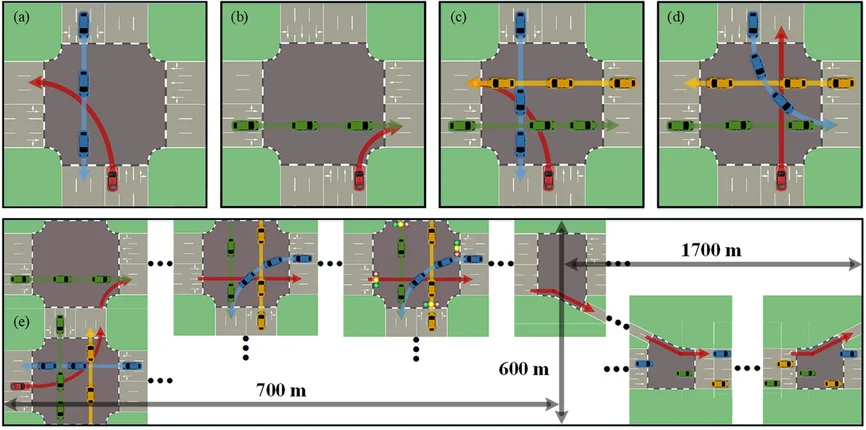
출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹 출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹
■ 대표적인 강화학습 알고리즘의 종류 1.Q러닝(Q-learning): 상태와 행동 쌍에 대한 값을 업데이트하여 최적의 정책을 학습하는 방법입니다. 2. SARSA: 현재 상태와 행동에 따라 값을 업데이트하는 방법입니다. 3. DQN(Deep Q-Networks) : 심층 신경망을 사용하여 Q-값을 근사하는 방법입니다. ■ 대표적인 강화학습 알고리즘의 종류 1.Q러닝(Q-learning): 상태와 행동 쌍에 대한 값을 업데이트하여 최적의 정책을 학습하는 방법입니다. 2. SARSA: 현재 상태와 행동에 따라 값을 업데이트하는 방법입니다. 3. DQN(Deep Q-Networks) : 심층 신경망을 사용하여 Q-값을 근사하는 방법입니다.
출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹 출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹
강화학습은 자율주행, 게임AI, 로봇공학 등 다양한 분야에서 응용되고 있습니다. 에이전트가 환경에서 학습하면서 스스로 최적의 행동을 찾는다는 점에서 매우 강력한 기법으로 평가받고 있습니다. 강화학습은 자율주행, 게임AI, 로봇공학 등 다양한 분야에서 응용되고 있습니다. 에이전트가 환경에서 학습하면서 스스로 최적의 행동을 찾는다는 점에서 매우 강력한 기법으로 평가받고 있습니다.
출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹 출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹
강화학습을 포함하여 지도학습과 비지도학습까지 기계학습 방법에 대해 알아봤습니다. 다음 시간에는 자기지도학습과 반지도학습에 대해 알아보도록 하죠 출처: 행복을 꿈꾸는 전자가게/카트로스/캡틴권/타이거권 강화학습을 포함하여 지도학습과 비지도학습까지 기계학습 방법에 대해 알아봤습니다. 다음 시간에는 자기지도학습과 반지도학습에 대해 알아보도록 하죠 출처: 행복을 꿈꾸는 전자가게/카트로스/캡틴권/타이거권
출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹 출처 : 행복을 꿈꾸는 전기집 / 카트로스 / 캡틴 주먹 / 타이거 주먹